




Home > Media News >

Source: https://techcrunch.com
data set of more than 3 million Facebook users and a variety of their personal details collected by Cambridge researchers was available for anyone to download for some four years, New Scientist reports. It’s likely only one of many places where such huge sets of personal data collected during a period of permissive Facebook access terms have been obtainable.
The data were collected as part of a personality test, myPersonality, which, according to its own wiki (now taken down), was operational from 2007 to 2012, but new data was added as late as August of 2016. It started as a side project by the Cambridge Psychometrics Centre’s David Stillwell (now deputy director there), but graduated to a more organized research effort later. The project “has close academic links,” the site explains, “however, it is a standalone business.” (Presumably for liability purposes; the group never charged for access to the data.)
Though “Cambridge” is in the name, there’s no real connection to Cambridge Analytica, just a very tenuous one through Aleksandr Kogan, which is explained below.
Like other quiz apps, it requested consent to access the user’s profile (friends’ data was not collected), which combined with responses to questionnaires produced a rich data set with entries for millions of users. Data collected included demographics, status updates, some profile pictures, likes and lots more, but not private messages or data from friends.
Exactly how many users are affected is a bit difficult to say: the wiki claims the database holds 6 million test results from 4 million profiles (hence the headline), though only 3.1 million sets of personality scores are in the set and far less data points are available on certain metrics, such as employer or school. At any rate, the total number is on that order, though the same data is not available for every user.

Although the data is stripped of identifying information, such as the user’s actual name, the volume and breadth of it makes the set susceptible to de-anonymization, for lack of a better term. (I should add there is no evidence that this has actually occurred; simple anonymizing processes on rich data sets are just fundamentally more vulnerable to this kind of reassembly effort.)
This data set was available via a wiki to credentialed academics who had to agree to the team’s own terms of service. It was used by hundreds of researchers from dozens of institutions and companies for numerous papers and projects, including some from Google, Microsoft, Yahoo and even Facebook itself. (I asked the latter about this curious occurrence, and a representative told me that two researchers listed signed up for the data before working there; it’s unclear why in that case the name I saw would list Facebook as their affiliation, but there you have it.)
This in itself is in violation of Facebook’s terms of service, which ostensibly prohibited the distribution of such data to third parties. As we’ve seen over the last year or so, however, it appears to have exerted almost no effort at all in enforcing this policy, as hundreds (potentially thousands) of apps were plainly and seemingly proudly violating the terms by sharing data sets gleaned from Facebook users.
In the case of myPersonality, the data was supposed to be distributed only to actual researchers; Stillwell and his collaborator at the time, Michal Kosinski, personally vetted applications, which had to list the data they needed and why, as this sample application shows:
I am a full-time faculty member. [IF YOU ARE A STUDENT PLEASE HAVE YOU SUPERVISOR REQUEST ACCESS TO THE DATA FOR YOU.] I read and agree with the myPersonality Database Terms of Use. [SERIOUSLY, PLEASE DO READ IT.] I will take responsibility for the use of the data by any students in my research group.
I am planning to use the following variables:
* [LIST THE VARIABLES YOU INTEND TO
* USE AND TELL US HOW
* YOU PLAN TO ANALYZE THEM.]
One lecturer, however, published their credentials on GitHub in order to allow their students to use the data. Those credentials were available to anyone searching for access to the myPersonality database for, as New Scientist estimates, about four years.
This seems to demonstrate the laxity with which Facebook was policing the data it supposedly guarded. Once that data left company premises, there was no way for the company to control it in the first place, but the fact that a set of millions of entries was being sent to any academic who asked, and anyone who had a publicly listed username and password, suggests it wasn’t even trying.
A Facebook researcher actually requested the data in violation of his own company’s policies. I’m not sure what to conclude from that, other than that the company was utterly uninterested in securing sets like this and far more concerned with providing against any future liability. After all, if the app was in violation, Facebook can simply suspend it — as the company did last month, by the way — and lay the whole burden on the violator.
“We suspended the myPersonality app almost a month ago because we believe that it may have violated Facebook’s policies,” said Facebook’s VP of product partnerships, Ime Archibong, in a statement. “We are currently investigating the app, and if myPersonality refuses to cooperate or fails our audit, we will ban it.”
In a statement provided to TechCrunch, David Stillwell defended the myPersonality project’s data collection and distribution.
“myPersonality collaborators have published more than 100 social science research papers on important topics that advance our understanding of the growing use and impact of social networks,” he said. “We believe that academic research benefits from properly controlled sharing of anonymised data among the research community.”
In a separate email, Michal Kosinski also emphasized the importance of the published research based on their data set. Here’s a recent example looking into how people assess their own personalities versus how those who know them do, and how a computer trained to do so performs.
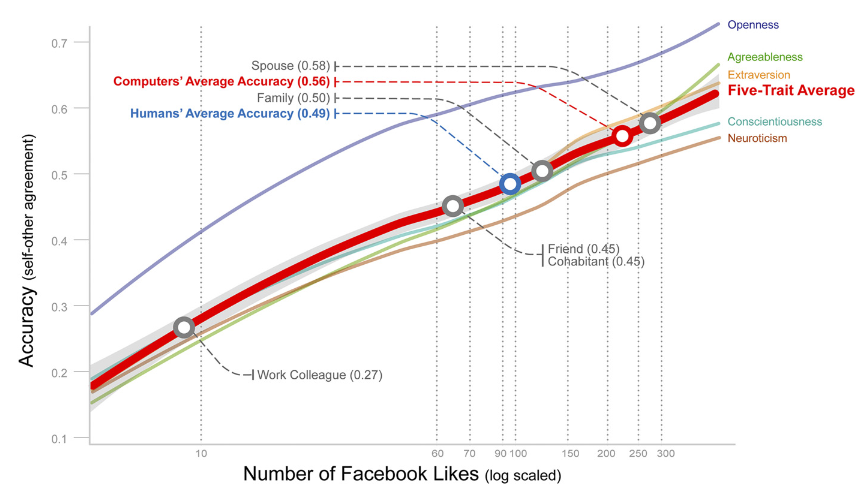
“Facebook has been aware of and has encouraged our research since at least 2011,” the statement continued. It’s hard to square this with Facebook’s allegation that the project was suspended for policy violations based on the language of its redistribution terms, which is how a company spokesperson explained it to me. The likely explanation is that Facebook never looked closely until this type of profile data sharing became unpopular, and usage and distribution among academics came under closer scrutiny.
Stillwell said (and the Centre has specifically explained) that Aleksandr Kogan was not in fact associated with the project; he was, however, one of the collaborators who received access to the data like those at other institutions. He apparently certified that he did not use this data in his SCL and Cambridge Analytica dealings.
The statement also says that the newest data is six years old, which seems substantially accurate from what I can tell except, for a set of nearly 800,000 users’ data regarding the 2015 rainbow profile picture filter campaign, added in August 2016. That doesn’t change much, but I thought it worth noting.
Facebook has suspended hundreds of apps and services and is investigating thousands more after it became clear in the Cambridge Analytica case that data collected from its users for one purpose was being redeployed for all sorts of purposes by actors nefarious and otherwise. One is a separate endeavor from the Cambridge Psychometrics Centre called Apply Magic Sauce; I asked the researchers about the connection between it and myPersonality data.
The takeaway from the small sample of these suspensions and collection methods that have been made public suggest that during its most permissive period (up until 2014 or so) Facebook allowed the data of countless users (the totals will only increase) to escape its authority, and that data is still out there, totally out of the company’s control and being used by anyone for just about anything.
Researchers working with user data provided with consent aren’t the enemy, but the total inability of Facebook (and to a certain extent the researchers themselves) to exert any kind of meaningful control over that data is indicative of grave missteps in digital privacy.
Ultimately it seems that Facebook should be the one taking responsibility for this massive oversight, but as Mark Zuckerberg’s performance in the Capitol emphasized, it’s not really clear what taking responsibility looks like other than an appearance of contrition and promises to do better.
Right Now

18 Jul, 2025 / 09:39 AM
Uber to invest 300 million-dollar in EV maker Lucid as part of robotaxi deal


21 Jul, 2025 / 08:40 AM
Google’s AI can now call local businesses to check prices and availability on your behalf
Top Stories


